一、核心概念定义
1. Prompt(提示词)
1.1. 定义:
Prompt即提示词,是向大语言模型(LLM)或AI Agent输入的结构化文本指令,是实现人机交互、引导模型输出符合预期结果的核心媒介。它通过明确的自然语言描述,向模型传递任务目标、执行方式、输出格式、上下文背景、示例参考等关键信息,是模型理解需求、生成响应的直接依据。
Prompt = 你对AI说的话
比如:
- “帮我写一篇关于春天的诗”
- “这段代码有什么bug?”
- “解释一下量子纠缠”
在Agent体系中,Prompt主要分为两类:
- 系统Prompt(System Prompt):预先设定的底层指令,定义Agent的核心身份、基础行为准则与通用输出规范,是Agent的“底层人设与基础指令”,通常固定不变。
- 用户Prompt(User Prompt):用户实时发起的具体任务请求、问题或交互内容,是Agent单次执行任务的直接触发指令。
1.2. Prompt的特点:
- 简单直接,就像你在跟人聊天
- 每次对话都可以不同
- 适合一次性任务
1.3. Prompt的问题:
- 如果你经常要做类似的事情,每次都要重新输入Prompt
- AI可能会”忘记”你之前的设置
- 无法复用和共享
2. Rules(规则)
2.1 定义:
Rules即规则,是为AI Agent设定的强制性约束、行为边界与合规准则,是不可违背的硬性规范,用于管控Agent的行为逻辑、输出内容与执行范围,避免模型出现偏差、违规或不符合业务需求的行为。
Rules = AI的行为准则
比如:
- “你是一个专业的程序员,写代码时要遵循PEP8规范”
- “回复时要简短精炼,不要超过100字”
- “遇到不确定的信息,要明确告诉用户”
规则的核心是“约束与边界”,常见类型包括:
- 安全合规规则:禁止输出违法、违规、暴力、歧视等不良内容的约束;
- 业务流程规则:限定Agent执行任务的流程、权限、数据访问范围;
- 输出格式规则:强制要求响应的结构、语气、字段完整性;
- 交互行为规则:限定Agent的对话风格、拒绝策略、异常处理方式。
2.2 Rules的特点:
- 一次设置,长期生效
- 定义了AI的”人设”和”行为模式”
- 适合长期稳定的需求
2.2 Rules的问题:
- 只能定义”做什么”和”不做什么”,无法定义”怎么做”
- 无法包含复杂的操作步骤
- 仍然比较抽象
3. Skills(技能)
3.1 定义:
Skills即技能,是AI Agent具备的可复用、模块化、可执行的任务能力集合,是Agent突破大模型原生能力局限、完成实际业务场景任务的核心支撑。技能是将抽象的任务需求转化为具体可执行动作的标准化单元。
Skills = AI的超能力模板
举个例子:
假设你经常需要从网页抓取数据并生成报告。
- 用Prompt:每次都要输入”帮我访问这个网页,提取XX数据,然后生成报告”
- 用Rules:可以设定”你是个数据分析师,生成报告时要包含XX部分”
- 用Skill:直接调用”网页数据抓取Skill”,它会自动完成访问→提取→分析→生成报告的全流程
Agent的技能通常分为三类:
- 原生推理技能:基于大模型自身能力的基础技能,如文本理解、逻辑推理、内容总结、语言翻译;
- 工具调用技能:对接外部系统/工具的扩展技能,如数据库查询、API调用、文档检索(RAG)、代码执行、数据分析;
- 自定义业务技能:针对特定行业场景封装的专属技能,如客服工单处理、财务报表生成、物流信息查询等。
3.2 一个Skill通常包含:
- Prompt模板:定义任务目标
- Rules:设定行为规范
- 操作步骤:具体的执行流程
- 工具调用:需要用到的外部工具或API
- 输出格式:标准化的结果呈现
3.3 Skills的特点:
- 完整性:从输入到输出的完整方案
- 可复用:一次创建,多次使用
- 可共享:可以被其他用户或Agent调用
- 可组合:多个Skill可以组合完成复杂任务
3.4 Skills的价值:
- 不用每次都重新描述需求
- 保证了输出的质量和一致性
- 可以在社区中共享和交换
- 让AI真正成为你的”数字员工”
4. MCP(Model Context Protocol,模型上下文协议)
4.1 定义:
MCP(Model Context Protocol)是一个技术协议,它的作用是让AI能够安全、规范地访问外部数据和服务。
它定义了 Agent 与外部资源之间的通信格式、连接方式、权限校验、工具发现、结果返回的统一标准,解决了以往模型对接不同工具时格式混乱、安全不可控、集成成本高的问题,被称为 AI 与外部世界的 “通用接口标准”。
MCP = AI和世界连接的协议
你可以把MCP理解成一套”插座标准”:
- AI是电器
- 外部系统(数据库、API、文件系统)是电源
- MCP是插座标准
4.2 MCP解决的问题:
- 安全问题:如何让AI安全地访问敏感数据
- 标准化问题:不同的系统用统一的方式连接
- 权限管理:AI能做什么、不能做什么
- 数据隔离:避免AI越界访问不该访问的内容
4.3 MCP与Skills的关系:
Skills是”做什么”,MCP是”怎么安全地做”。
一个Skill在执行过程中,如果需要访问外部系统,就会通过MCP协议来连接。
二、Prompt、Rules、Skills、MCP之间的关系
四者构成「需求触发 → 规则校验 → 能力匹配 → 协议通信 → 结果返回」的完整闭环,是层级分工明确、依次协同、缺一不可的关系,下面从层级定位、动态工作流、两两关联三个维度详细说明。
(一)层级定位关系:四层协同,自上而下驱动
从任务执行的逻辑层级来看,四者形成清晰的自上而下的驱动与支撑结构,每一层都为下一层提供约束或输入,下一层为上一层提供执行保障:
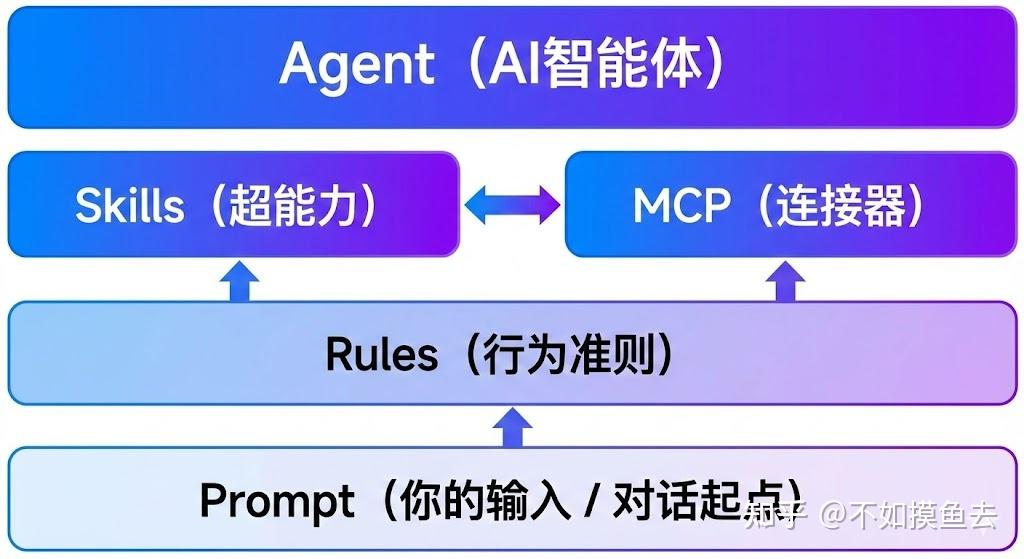
- Prompt:是你和AI对话的起点
- Rules:定义AI的基本行为规范
- Skills:封装了完整的任务解决方案
- MCP:让AI能够安全地连接外部世界
| 层级 | 概念 | 核心定位 | 核心职责 | 与其他层的关系 |
|---|---|---|---|---|
| 第1层(需求层) | Prompt | 任务发起者 | 提出具体任务需求,传递上下文 | 触发后续所有流程,是整个链路的源头 |
| 第2层(管控层) | Rules | 行为约束者 | 校验需求合规性,管控执行边界 | 对 Prompt 的需求进行约束,同时限定 Skills 的调用范围与 MCP 的通信权限 |
| 第3层(能力层) | Skills | 能力执行者 | 匹配需求,提供具体业务能力 | 响应 Prompt 的需求,受 Rules 约束,依赖 MCP 实现外部能力的落地 |
| 第4层(通信层) | MCP | 标准连接器 | 提供安全规范的外部通信通道 | 为 Skills 提供标准化的外部调用接口,执行 Rules 中定义的权限与安全规则 |
(二)动态协同工作流:完整的 Agent 任务执行过程
结合实际业务场景,以「Agent 查询企业月度销售数据并生成报表」为例,完整演示四者的协作流程:
Prompt 发起需求
用户输入 Prompt:「请查询我司2025年12月的销售数据,并生成一份Excel格式的销售报表」。
系统 Prompt 预先定义:「你是企业财务智能助手,仅可访问销售数据库,输出需合规,禁止泄露敏感数据」。Rules 执行合规校验
Agent 基于预设 Rules 对 Prompt 进行校验:- 校验权限规则:确认该请求属于销售数据查询范畴,允许访问对应数据库;
- 校验合规规则:确认无敏感信息泄露风险,允许生成报表;
- 校验流程规则:规定需先查询数据,再生成报表,不可颠倒执行。
校验通过后,进入能力匹配环节。
Skills 匹配并发起能力调用
Agent 根据 Prompt 需求,匹配对应的 Skills:- 匹配「销售数据库查询 Skill」:用于获取原始销售数据;
- 匹配「Excel 报表生成 Skill」:用于将数据格式化为报表。
此时,Skills 本身无法直接连接外部数据库和文件服务,需要依赖标准化的通信通道。
MCP 提供标准化通信支撑
Skills 通过 MCP 协议 与外部资源进行安全交互:- MCP 按照协议规范,封装数据库查询请求,携带身份与权限凭证;
- MCP Server 端校验 Rules 中定义的访问权限,验证通过后执行查询;
- 查询结果通过 MCP 协议标准化返回给 Agent;
- 后续「Excel 报表生成 Skill」同样通过 MCP 协议,安全调用文件生成服务,完成报表制作。
结果输出与最终校验
报表生成后,再次通过 Rules 校验输出格式与内容合规性,最终将结果返回给用户,完成整个任务闭环。
(三)两两之间的核心关联
1. Prompt ↔ Rules
- Prompt 提出任务需求,Rules 对该需求进行强制性约束与合规审查,决定该需求是否允许执行、以何种方式执行。
- 系统 Prompt 中通常会嵌入基础的 Rules 描述,而独立的 Rules 模块则是更工程化、可动态配置的约束体系,对 Prompt 形成补充和强管控。
- 若 Prompt 触发违规需求,Rules 会直接拦截,终止后续流程。
2. Prompt ↔ Skills
- Prompt 是 Skills 的唯一触发源,Skills 是实现 Prompt 需求的能力载体。
- 简单的 Prompt(如文本翻译)可仅依赖模型原生 Skills 完成;复杂的 Prompt(如查询数据、生成报表)必须调用外部扩展 Skills 才能落地。
- Agent 会通过理解 Prompt 的语义,自动匹配并激活对应的 Skills。
3. Skills ↔ MCP
- Skills 是能力的逻辑定义,MCP 是能力的物理执行通道。
- 所有需要访问外部工具、数据源的 Skills,都必须通过 MCP 协议完成通信,MCP 为 Skills 提供统一的调用标准、安全校验和结果解析。
- MCP 解决了 Skills 对接外部资源的碎片化问题,让不同的 Skills 可以用同一套协议规范连接各类外部服务。
4. Rules ↔ MCP
- Rules 定义权限与安全策略,MCP 负责落地执行这些策略。
- Rules 中规定的“可访问的数据源”“可调用的工具列表”“传输加密要求”等,都会转化为 MCP 通信过程中的校验规则。
- MCP 在建立连接、传输数据、返回结果的全流程中,都会实时遵循 Rules 的约束,确保通信行为合规安全。
5. Prompt ↔ MCP
- 二者无直接交互,Prompt 不直接调用 MCP。
- Prompt 通过触发 Skills,间接驱动 MCP 启动通信流程;MCP 的执行结果,最终会被整合后,以符合 Prompt 要求的形式返回给用户。
三、关系总结
- Prompt 是起点:提出任务需求,开启整个 Agent 执行流程,决定任务的目标与方向。
- Rules 是底线:全程管控行为边界与合规性,保障 Agent 安全、有序地执行任务,约束 Prompt、Skills、MCP 的所有行为。
- Skills 是核心能力:承接 Prompt 的需求,提供具体的业务执行能力,是 Agent 完成复杂任务的关键。
- MCP 是底层支撑:作为标准化通信协议,为 Skills 提供安全、规范的外部资源访问通道,是 Skills 落地外部能力的技术基础。
整体而言,四者的关系可以概括为:Prompt 发令,Rules 把关,Skills 办事,MCP 铺路,共同构成了现代 AI Agent 从需求接收到任务完成的完整能力体系。
]]>