Java 中数据结构的使用主要分两大层面:一是原生基础数据结构(Java 语言直接支持,是所有高级结构的底层基石),二是集合框架封装的常用数据结构(Java 官方封装好、开箱即用,也是实际开发中最常使用的,无需自己手动实现);此外还有并发包专用的高级数据结构(适配多线程场景)。
这些数据结构覆盖了开发中绝大多数场景,且 Java 对底层复杂逻辑(如红黑树旋转、哈希冲突解决)做了高度封装,开发者只需关注使用场景而非底层实现,下面按「基础→核心常用→并发专用」的逻辑梳理,同时结合实际使用类和适用场景说明,贴合开发实际。
一、Java 原生基础数据结构(底层基石)
这类结构是 Java 语言本身支持的,无专门的类,但会被所有高级集合底层大量使用,是理解集合框架的基础。
数组(Array)
- 特点:连续内存存储、固定长度、支持随机访问(通过索引
O(1)取值)、增删元素需移动数据(O(n)效率)。 - Java 中使用:直接声明
int[] arr、String[] strs,或泛型数组T[](需反射创建)。 - 应用:ArrayList、ArrayDeque、HashMap(数组+链表/红黑树)的底层核心。
- 特点:连续内存存储、固定长度、支持随机访问(通过索引
链表(Linked List)
- 特点:非连续内存存储(节点通过指针/引用连接)、长度动态、增删节点仅需修改引用(
O(1)效率)、查询需遍历(O(n)效率)。 - Java 中无原生链表类,但底层大量实现:双向链表是主流(LinkedList、LinkedHashMap、LinkedHashSet 底层),单向链表仅在早期 HashMap 中使用(JDK8 后已优化)。
- 核心节点结构:包含「数据域」+「前驱节点引用」+「后继节点引用」(双向链表)。
- 特点:非连续内存存储(节点通过指针/引用连接)、长度动态、增删节点仅需修改引用(
二、Java 集合框架核心数据结构(开发中最常使用)
Java 集合框架(java.util 包)是数据结构的核心应用,分为Collection(单列集合)和Map(双列键值对集合)两大根接口,所有实现类都封装了具体的数据结构,无需自己手动实现链表/红黑树/哈希表,直接用即可。
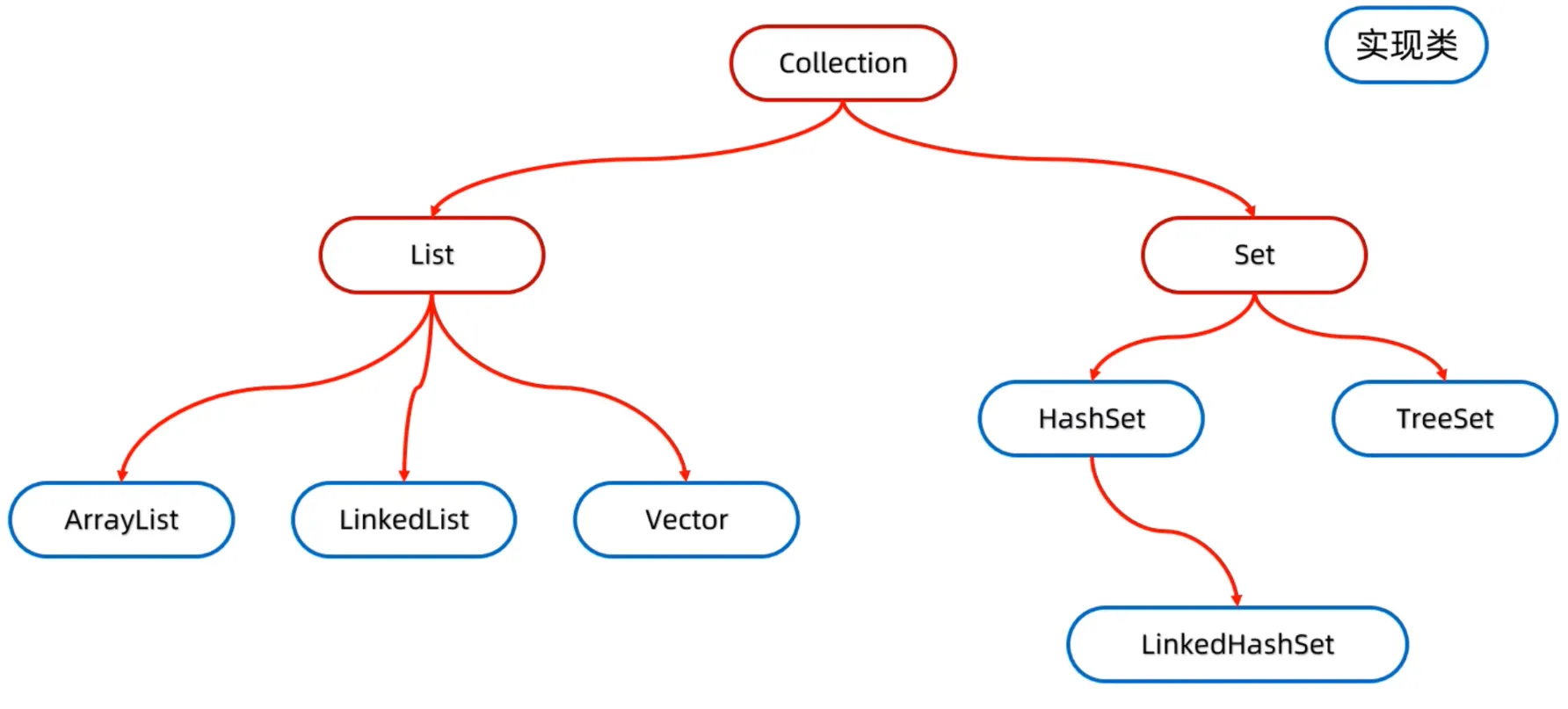
(一)Collection 接口下的结构(List/Set/Queue)
1. 有序可重复:List 接口
对应 2 种核心数据结构,覆盖「查询多」和「增删多」两种核心场景:
| 实现类 | 底层数据结构 | 核心特点 | 适用场景 |
|---|---|---|---|
| ArrayList | 动态扩容数组 | 查询快、尾插快、中间增删慢 | 绝大多数场景(查询远多于增删) |
| LinkedList | 双向链表(双端队列) | 增删快、查询慢、支持栈/队列 | 频繁在中间增删、需栈/队列功能 |
注:Vector 是 ArrayList 的线程安全版(底层也是动态数组),但效率低,开发中几乎不用,被 ConcurrentArrayList 替代。
2. 无序不可重复:Set 接口
Set 本身不存数据,底层依赖 Map 实现(用 Map 的键存值,值为固定空对象),核心是去重,对应 3 种结构:
| 实现类 | 底层依赖的 Map | 底层数据结构 | 核心特点 | 适用场景 |
|---|---|---|---|---|
| HashSet | HashMap | 哈希表(数组+链表+红黑树) | 无序、去重、查询/增删快 | 仅需去重,无需有序 |
| LinkedHashSet | LinkedHashMap | 哈希表+双向链表 | 有序(插入顺序)、去重 | 去重且需保留插入顺序 |
| TreeSet | TreeMap | 红黑树(自平衡二叉搜索树) | 有序(自然/自定义排序) | 去重且需排序 |
3. 队列/双端队列:Queue/Deque 接口
用于「先进先出(FIFO)」或「双端操作」场景,底层以循环数组和双向链表为主(循环数组效率更高):
| 实现类 | 底层数据结构 | 核心特点 | 适用场景 |
|---|---|---|---|
| ArrayDeque | 循环数组 | 无容量限制、两端操作快 | 替代 Stack 做栈、普通队列 |
| LinkedList | 双向链表 | 支持两端操作、可存null | 需存null的队列场景 |
| PriorityQueue | 堆(默认小顶堆) | 有序(优先级排序) | 按优先级取数据(如任务调度) |
注:Stack 类(Java 原生栈)底层是 Vector(动态数组),效率低且设计有缺陷,开发中推荐用 ArrayDeque 替代(调用
push/pop/peek方法即可实现栈的功能)。
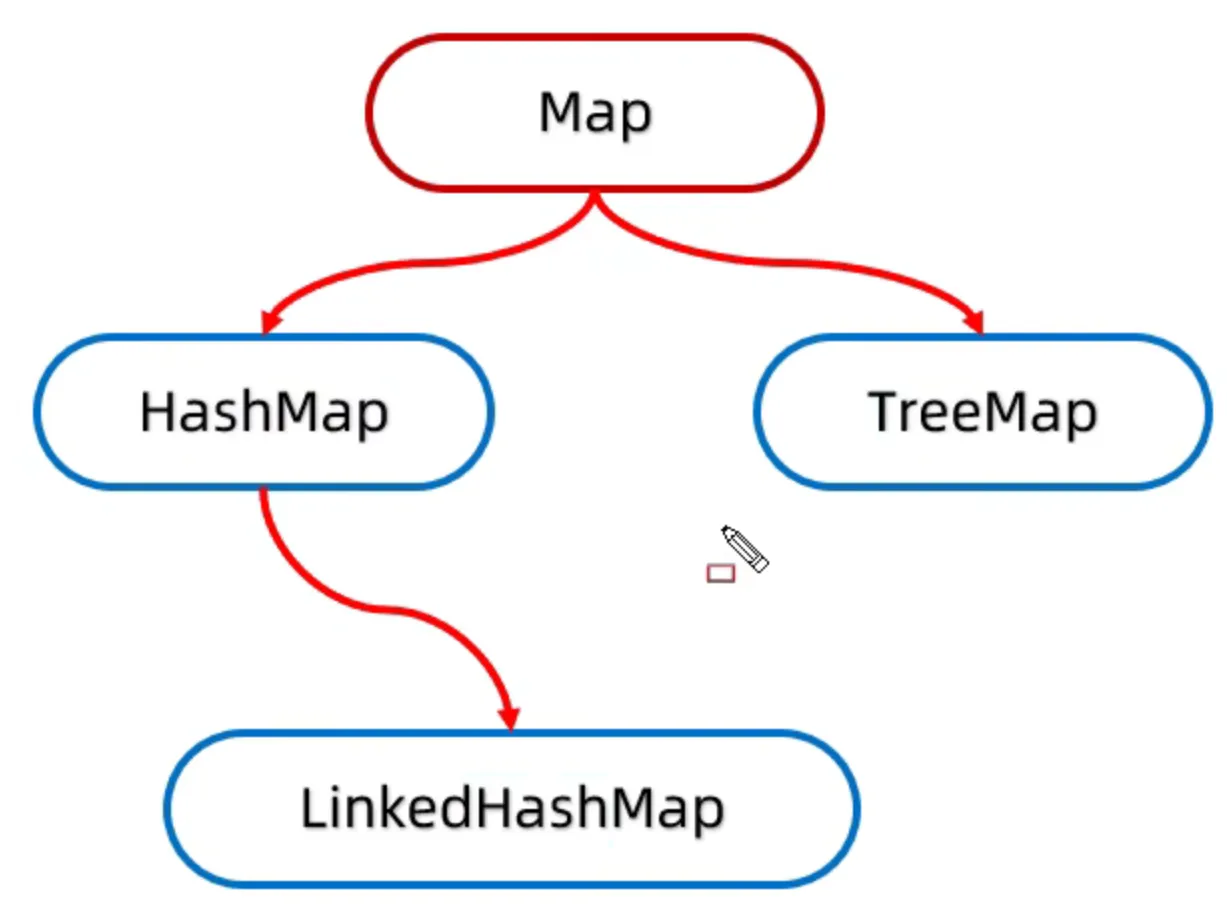
(二)Map 接口下的结构(双列键值对,核心去重+映射)
Map 是开发中使用频率最高的集合(如存储配置、缓存、对象映射),核心是键唯一,值可重复,底层以哈希表为主,红黑树为辅,主流实现类如下:
| 实现类 | 底层数据结构 | 核心特点 | 适用场景 |
|---|---|---|---|
| HashMap | 哈希表(JDK8+:数组+链表+红黑树) | 无序、键值可存null、查询/增删快(O(1)) | 绝大多数键值对场景(非并发) |
| LinkedHashMap | HashMap+双向链表 | 有序(插入/访问顺序)、键值可存null | 需保留键的插入/访问顺序(如LRU缓存) |
| TreeMap | 红黑树 | 有序(键的自然/自定义排序)、键不可存null | 键值对需按键排序 |
| Hashtable | 哈希表(数组+链表) | 线程安全、键值不可存null、效率低 | 几乎不用(被 ConcurrentHashMap 替代) |
关键知识点:HashMap 是核心,JDK8 对其做了重大优化——当哈希冲突导致链表长度超过8,且数组长度≥64时,链表会转为红黑树,将查询效率从
O(n)提升到O(logn)。
三、Java 并发包中的专用数据结构(多线程场景)
在多线程开发中,普通集合(如 ArrayList、HashMap)是非线程安全的,Java 并发包(java.util.concurrent,简称 JUC)封装了线程安全的高级数据结构,底层结合了 CAS、分段锁、无锁算法等,同时封装了特殊结构(如跳表、阻塞队列),核心常用如下:
1. 并发 Map 结构
| 实现类 | 底层数据结构 | 线程安全实现方式 | 适用场景 |
|---|---|---|---|
| ConcurrentHashMap | 哈希表(数组+链表+红黑树) | JDK8+:CAS + 局部Synchronized | 高并发下的键值对场景(核心推荐) |
| ConcurrentSkipListMap | 跳表(SkipList) | 无锁算法 | 高并发+需有序的键值对场景 |
跳表:一种有序的高效查找结构,底层是「多层链表」,查询效率
O(logn),比红黑树实现更简单,适合并发场景。
2. 并发队列/阻塞队列(JUC 核心,多线程通信)
阻塞队列(BlockingQueue)是多线程通信的核心(如生产者-消费者模型),底层为循环数组或双向链表,支持「满时阻塞生产者、空时阻塞消费者」,核心实现:
| 实现类 | 底层数据结构 | 核心特点 | 适用场景 |
|---|---|---|---|
| ArrayBlockingQueue | 循环数组(有界) | 固定容量、效率高 | 需限制队列大小的生产消费 |
| LinkedBlockingQueue | 双向链表(无界/有界) | 容量可选、吞吐量高 | 无固定容量限制的生产消费 |
| SynchronousQueue | 无底层存储(中转) | 生产消费直接交换 | 高吞吐、低延迟的线程通信 |
| DelayQueue | 堆 | 按延迟时间排序 | 定时任务(如超时订单处理) |
此外还有无锁并发队列(ConcurrentLinkedQueue/ConcurrentLinkedDeque),底层为双向链表,基于 CAS 实现,适合高并发但无需阻塞的场景。
四、Java 中少见但实用的特殊数据结构
除上述核心结构外,Java 还在特定包中实现了一些小众但实用的结构,适用于特殊场景:
- 位图(BitSet):
java.util.BitSet,底层是长整型数组,用二进制位存储数据,适合「海量数据去重、状态标记」(如判断 1000 万个数中是否存在某个数,占用内存极少)。 - 堆(Heap):Java 无原生堆类,但 PriorityQueue 是堆的实现(默认小顶堆,可通过比较器改为大顶堆),适用于TopK、优先级排序场景。
- 红黑树(Red-Black Tree):Java 无原生红黑树类,但 TreeMap/TreeSet 底层是红黑树,是自平衡的二叉搜索树,保证增删查的效率均为
O(logn)。 - 哈希表(Hash Table):Java 无原生哈希表类,但 HashMap/HashSet/Hashtable 都是哈希表的实现,核心是「哈希函数+数组+冲突解决」(JDK8 后用链表+红黑树解决冲突)。
五、Java 数据结构核心使用原则(开发避坑)
- 查询多、增删少→用数组结构(ArrayList),增删多、查询少→用链表结构(LinkedList);
- 仅去重→HashSet,去重+有序→LinkedHashSet,去重+排序→TreeSet;
- 普通键值对→HashMap,键值对+有序→LinkedHashMap/TreeMap,高并发键值对→ConcurrentHashMap;
- 栈/队列→优先用 ArrayDeque(替代 Stack、LinkedList),优先级队列→PriorityQueue;
- 多线程场景→必须用 JUC 包的并发结构,禁止用普通集合(如 ArrayList、HashMap)加锁(效率低且易出问题);
- 海量数据去重/状态标记→BitSet(比 HashSet 节省百倍内存)。
总结
Java 中数据结构的使用无需手动实现底层,核心是根据场景选择集合框架的实现类,关键记住「集合类→底层数据结构→核心特点」的对应关系,核心梳理如下:
- 基础底层:数组、双向链表(所有高级集合的基石);
- 核心常用:哈希表(HashMap/HashSet)、动态数组(ArrayList)、双向链表(LinkedList)、红黑树(TreeMap/TreeSet)、堆(PriorityQueue)、循环数组(ArrayDeque);
- 并发专用:CAS 实现的哈希表(ConcurrentHashMap)、跳表(ConcurrentSkipListMap)、阻塞队列(ArrayBlockingQueue/LinkedBlockingQueue);
- 特殊场景:位图(BitSet)、无锁队列(ConcurrentLinkedQueue)。
实际开发中,ArrayList、HashMap、HashSet、ArrayDeque 是使用频率最高的四个类,覆盖了 80% 以上的常规场景,掌握它们的底层结构和使用场景,就掌握了 Java 数据结构的核心。
__END__
